


Switching Mastodon from Scaleway S3 to self-hosted Minio S3 media storage
Since the user flood of November 2022 I’ve been using Scaleway’s S3 storage for media file caching and storage of my metalhead.club Mastodon instance. It was easy to set up and has been working reliably for me. Back then the media cache size increased so much that my server’s internal storage could not keep up with the increasing demand. I didn’t want to shrink down the cache duration too much and therefore left it at 14 days. At the time, the cache was about 800 GB in size - a big mass of image files that could not be handled by my aged server itself.
metalhead.club was moved to a more powerful, new server in April. The new server was built to have plenty of storage for Mastodon media storage. I planned to move the S3 storage back to my own infrastructure to save costs. Although media file requests have always been cached by my own HTTP proxy and Scaleway did not get any user-related metadata, it also feels better to have more control and not depend on any 3rd party services for such an essential part of my social network software.
(… and there have been short service interruptions that we’ve had several times in the past. The overall experience has been decent, but I hoped to achieve better availability by running S3 myself ;-) )
As an S3 compatible storage software I chose Minio. I’ve never setup and run my own Minio instance before, but I’ve heard good things about the project that is usually used in big cloud computing setups. A quick glimpse at the documentation revealed that running my own simple Minio instance would just be a matter of minutes - given that the software can easily deployed via Docker. The “single node - single drive” operating mode of Minio is sufficient for now. I’m not expecting any exponential growth of my Mastodon instance anywhere in the future, so I kept the setup as small and simple as possible. No redundancies (already covered by a lower-layer storage backend) and just a single node.
This article does not aim to be a complete guide, because several days have passed since I implemented my S3 server and I might not remember every detail. Nevertheless I’d like to put some notes about the setup here. Just in case it is interesting for anybody.
Basic Minio setup using Podman
Like I mentioned - Minio can bew run as a Docker container. I’m not that much a fan of Docker deployments, so chose Podman instead. Podman lets my run Minio “root-less”, which adds extra security. As the root user, I installed Podman and created a new user for Minio on my system:
apt install podman uidmap slirp4netns
mkdir /opt/minio
useradd -s /usr/sbin/nologin --home-dir /opt/minio minio
chown minio:minio /opt/minio
Now create a directory for Minio to store its data, e.g.:
sudo mkdir /var/lib/minio
sudo chown minio:minio /var/lib/minio
The minio user is not allowed to log in via a login shell. But you can switch to it by using this command as root:
su -s /bin/bash - minio
The minio user will run the Podman-managed container. As the minio user, the Podman container for Minio is downloaded:
podman pull quay.io/minio/minio
If you see this message:
Error: command required for rootless mode with multiple IDs: exec: “newuidmap”: executable file not found in $PATH
log out from your account and log back in. The problem should be fixed then. If not, make sure that package newuidmap is installed.
Next the environment variable file is created. It will be located on the container host, but be mounted inside the Minio container so Minio can read it and configure itself according to it.
Create the file /opt/minio/config.env:
MINIO_SERVER_URL="https://s3.mydomain.tld"
MINIO_DOMAIN="s3.mydomain.tld"
MINIO_ROOT_USER="myadminuser"
MINIO_ROOT_PASSWORD="mysupepoassword"
MINIO_REGION=myregion
MINIO_SERVER_URL: Public URL of your S3 serviceMINIO_DOMAIN: Domain part of the Public URL. Used my Minio to enable addressing Buckets via subdomain, e.g.mybucket.s3.mydomain.tldMINIO_ROOT_USERandMINIO_ROOT_PASSWORD: Admin user and password for Minio Console.MINIO_REGION: “Availablity region” of this S3 server. I used my physical server’s hostname here.
Afterwards, it’s time to start up the container for the first time:
podman run -dt \
-p 9000:9000 \
-p 9090:9090 \
-v /var/lib/minio:/mnt/data \
-v /opt/minio/config.env:/etc/config.env \
-e MINIO_CONFIG_ENV_FILE=/etc/config.env \
--name minio \
quay.io/minio/minio \
server /mnt/data --console-address ":9090"
/var/lib/minio is the path to the Minio S3 storage. In my case it’s just the path to the mount point of an ext4 formatted virtual drive. All S3 files will reside there.
After starting up the container you should already be able to see container details via podman ps and connect to the admin console at http://s3.mydomain.tld:9090 and log in as your admin user (given that no firewall is blocking access).
Letting systemd start the container
Podman is a daemon-less container manager and cannot start or restart containers by itself. To start the Minio container after a reboot, I use a systemd user service that can easily be generated by podman. To make systemd user services work, enable user lingering (switch to root user for the next two lines):
loginctl enable-linger $(id -u minio)
systemctl start user@$(id -u minio).service
and put the following lines into ~/.profile:
(return to minio user before, using su -s /bin/bash - minio!)
export XDG_RUNTIME_DIR="/run/user/$(id -u)"
export DBUS_SESSION_BUS_ADDRESS="unix:path=/run/user/$(id -u)/bus"
Next, create the user service file:
mkdir -p ~/.config/systemd/user/
podman generate systemd --new --name minio > ~/.config/systemd/user/container-minio.service
… and enable the new Minio service:
systemctl --user daemon-reload
systemctl --user enable container-minio.service
if you ever want to modify the podman run parameters, make your changes in ~/.local/systemd/user/container-minio.service and restart the Minio service using
systemctl --user daemon-reload
systemctl --user restart container-minio.service
Your Minio container should automatically start after a reboot from now on.
Nginx reverse proxy config
I use Nginx for handling HTTPS connections. A suitable configuration might look like this:
upstream minio {
server 127.0.0.1:9000;
}
server {
listen 80;
listen [::]:80;
listen 443 ssl;
listen [::]:443 ssl;
# regex: Make bucket subdomains work
server_name ~^([^.]+).s3.mydomain.tld s3.mydomain.tld;
include snippets/tls-common.conf;
ssl_certificate /etc/acme.sh/s3.mydomain.tld/fullchain.pem;
ssl_certificate_key /etc/acme.sh/s3.mydomain.tld/privkey.pem;
# Allow special characters in headers
ignore_invalid_headers off;
# Allow any size file to be uploaded.
# Set to a value such as 1000m; to restrict file size to a specific value
client_max_body_size 0;
# Disable buffering
proxy_buffering off;
proxy_request_buffering off;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 300;
# Default is HTTP/1, keepalive is only enabled in HTTP/1.1
proxy_http_version 1.1;
proxy_set_header Connection "";
chunked_transfer_encoding off;
proxy_pass http://minio; # This uses the upstream directive definition to load balance
}
}
This Nginx virtual host at s3.mydomain.tld will serve all requests to the Minio S3 server.
Nginx reverse proxy for Minio console
There is an extra Nginx virtual host config.s3.mydomain.tld for the Minio console:
server {
listen 80;
listen [::]:80;
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name console.s3.mydomain.tld;
include snippets/tls-common.conf;
ssl_certificate /etc/acme.sh/s3.mydomain.tld/fullchain.pem;
ssl_certificate_key /etc/acme.sh/s3.mydomain.tld/privkey.pem;
# Allow special characters in headers
ignore_invalid_headers off;
# Allow any size file to be uploaded.
# Set to a value such as 1000m; to restrict file size to a specific value
client_max_body_size 0;
# Disable buffering
proxy_buffering off;
proxy_request_buffering off;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-NginX-Proxy true;
# This is necessary to pass the correct IP to be hashed
real_ip_header X-Real-IP;
proxy_connect_timeout 300;
# To support websockets in MinIO versions released after January 2023
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
chunked_transfer_encoding off;
proxy_pass http://127.0.0.1:9090; # This uses the upstream directive definition to load balance
}
}
Creating an S3 bucket for Mastodon
After logging in to Minio admin dashboard / console at console.s3.mydomain.tld, I created a new S3 bucket for my metalhead.club metalheadclub-media. It is important to set the bucket access rules correctly:
I’ve set a a new policy in the “Administrator” => “Policies” menu. “Create Policy”, then:
Name: “masto-public-read-nolist”
In the bucket settings, I’ve set the “Access Policy” to “Custom” and entered this configuration:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"*"
]
},
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::metalheadclub-media/*"
]
}
]
}
It allows all users from the internet to access the files in the bucket. But it does not allow to list the files in the bucket!. This is important because once the file list is available to the public, everyone will be able to download the full S3 bucket, which can (and probably will) contain sensitive information that must not be available to anyone except the information owners. If the file listing is turned off, it it simply not possible to guess all the random URLs and such an attack is avoided. This is the exact security issue that Mastodon.social had a while back. We definitely want to avoid that!
Creating an API key for Mastodon S3 access
The Mastodon software needs a new API key and secret to access the S3 bucket. Other than any anonymous public user, Mastodon must be allowed write access to the S3 bucket. In the Minio console go to “Access Keys” and create a new key. (Click “create”).
Copy the API key and secret to your password safe - the secret will never be displayed again!
Then click on the API key that was just created to edit its permissions. Set the following permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::metalheadclub-media"
]
},
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::metalheadclub-media/*"
]
}
]
}
(as always - adapt to your own bucket name!)
Save the bucket key and secret for later - they will be needed inside Mastodon’s live/.env.production file.
Caching Mastodon media files
But there is another Nginx virtual host specifically for my Mastodon instance: media.metalhead.club. I’ve used the domain for my media files on Scaleway before. My own media proxy does not only allow me to protect my users’ data towards 3rd party S3 services, but also cache the media files (and thus reducing the load/traffic to my S3 bucket) and make user-transparent S3 migrations:
proxy_cache_path /tmp/nginx-cache-metalheadclub-media levels=1:2 keys_zone=s3_cache:10m max_size=10g
inactive=48h use_temp_path=off;
server {
listen 80;
listen [::]:80;
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name media.metalhead.club;
include snippets/tls-common.conf;
ssl_certificate /etc/acme.sh/media.metalhead.club/fullchain.pem;
ssl_certificate_key /etc/acme.sh/media.metalhead.club/privkey.pem;
client_max_body_size 100M;
# Register backend URLs
set $scaleway_backend 'https://metalheadclub-media.s3.fr-par.scw.cloud';
set $minio_backend 'https://metalheadclub-media.s3.650thz.de';
# Note: We cannot use both @minio and @scaleway here, because only one named location is accepted with try_files
# Workaround: proxy_intercept_errors section and forwarding to @scaleway if @minio throws 404
# See: https://stackoverflow.com/questions/21286850/nginx-try-files-with-multiple-named-locations
location / {
access_log off;
try_files $uri @minio;
}
#
# Own Minio S3 server (new)
#
location @minio {
limit_except GET {
deny all;
}
resolver 8.8.8.8;
proxy_set_header Host 'metalheadclub-media.s3.650thz.de';
proxy_set_header Connection '';
proxy_set_header Authorization '';
proxy_hide_header Set-Cookie;
proxy_hide_header 'Access-Control-Allow-Origin';
proxy_hide_header 'Access-Control-Allow-Methods';
proxy_hide_header 'Access-Control-Allow-Headers';
proxy_hide_header x-amz-id-2;
proxy_hide_header x-amz-request-id;
proxy_hide_header x-amz-meta-server-side-encryption;
proxy_hide_header x-amz-server-side-encryption;
proxy_hide_header x-amz-bucket-region;
proxy_hide_header x-amzn-requestid;
proxy_ignore_headers Set-Cookie;
proxy_pass $minio_backend$uri;
#proxy_intercept_errors off;
# Caching to avoid S3 access
proxy_cache s3_cache;
proxy_cache_valid 200 304 48h;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_cache_lock on;
proxy_cache_revalidate on;
expires 1y;
add_header Cache-Control public;
add_header 'Access-Control-Allow-Origin' '*';
add_header X-Cache-Status $upstream_cache_status;
# Workaround: Forward request to @scaleway if @minio returns 404
proxy_intercept_errors on;
recursive_error_pages on;
error_page 404 = @scaleway;
}
#
# Scaleway S3 server (legacy)
#
location @scaleway {
limit_except GET {
deny all;
}
resolver 8.8.8.8;
proxy_set_header Host 'metalheadclub-media.s3.fr-par.scw.cloud';
proxy_set_header Connection '';
proxy_set_header Authorization '';
proxy_hide_header Set-Cookie;
proxy_hide_header 'Access-Control-Allow-Origin';
proxy_hide_header 'Access-Control-Allow-Methods';
proxy_hide_header 'Access-Control-Allow-Headers';
proxy_hide_header x-amz-id-2;
proxy_hide_header x-amz-request-id;
proxy_hide_header x-amz-meta-server-side-encryption;
proxy_hide_header x-amz-server-side-encryption;
proxy_hide_header x-amz-bucket-region;
proxy_hide_header x-amzn-requestid;
proxy_ignore_headers Set-Cookie;
proxy_pass $scaleway_backend$uri;
proxy_intercept_errors off;
proxy_cache s3_cache;
proxy_cache_valid 200 304 48h;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_cache_lock on;
proxy_cache_revalidate on;
expires 1y;
add_header Cache-Control public;
add_header 'Access-Control-Allow-Origin' '*';
add_header X-Cache-Status $upstream_cache_status;
}
}
There are a few notable lines here:
proxy_cache_pathadds a cache directory for requests to any S3 resource.proxy_cache s3_cachewill enable the cache. Thsi reduces load and traffic to the S3 buckets. Since media files are immutable once they are in the S3 storage, we can keep them in the cache them for a long time.set $scaleway_backendandset $minio_backendset the URLs of the S3 storage backends.try_files $uri @minio;will try to read a file from the local web root (rootdirective) first and try the minio backend second.@minioandscalewaylocationblocks: There is a proxy configuration for each of the S3 backends. The@minio“named location” will point to my own new Minio based S3 service.@scalewaywill point to the 3rd party S3 bucket hosted by my previous S3 provider.
If Minio is not able to serve a certain file, Scaleway will be asked to deliver the file.
By the way: You might think “Why not use something like try_files $uri @minio @scaleway; to implement a Fall-Back to Scaleway? Well, turns out that try_files only supports a single “named location(@)”, so this does not work. Instead I used another method to fall back to Scaleway:
# Workaround: Forward request to @scaleway if @minio returns 404
proxy_intercept_errors on;
recursive_error_pages on;
error_page 404 = @scaleway;
Another important note: the line
proxy_set_header Host 'metalheadclub-media.s3.650thz.de';
is important since it will set the Host header to a fictional / internal subdomain that is not used in public - but Minio will expect to receive this header so it knows which bucket (metalheadclub-media) is to be addressed. If the Host header is not set correctly, it will not know and will return an error.
The migration plan
I wanted to make the S3 migration from Scaleway to Minio as seamless as possible. My Mastodon users should not notice the switch - and here’s how I did it:
- I configured Mastodon to use the new Minio based S3 storage for any media uploads (
live/.env.productionon the Mastodon server):
S3_ENABLED=true
S3_BUCKET=metalheadclub-media
AWS_ACCESS_KEY_ID=secretkeyid
AWS_SECRET_ACCESS_KEY=secretaccesstoken
S3_ALIAS_HOST=media.metalhead.club
S3_REGION=hyper2
S3_PROTOCOL=https
S3_HOSTNAME=media.metalhead.club
S3_ENDPOINT=https://s3.650thz.de
S3_SIGNATURE_VERSION=v4
(then restarted all Mastodon services to apply changes).
I switched the DNS from my old Nginx media proxy to the new one (with Scaleway + Minio backend): The media proxy will now check if the requested media file exists on Minio S3 - if not, it will download from the legacy Scaleway storage. => New uploads get served by Minio, old ones by Scaleway.
I triggered a S3 files sync using
rclonefor media that was uploaded by metalhead.club users (and therefore is not “cached remote media”)There will be less S3 requests to Scaleway day after day, since the number of requests to the old Mastodon media cache will decline over time.
At some point the Scaleway S3 storage will not be accessed at all anymore, because all media files have either been transferred to Minio (user owned file uploads) or are not relevant anymore (cached media thumbnails, … - get invalid after a couple of days anyway)
Cloning existing instance user data to the new storage
Rclone is an awesome tool for copying files from one S3 bucket to another. I’ve created S3 storage configurations for both, Scaleway S3 and Minio S3 by running the rclone config guide, and here’s the result as a text configuration file (in ~/.config/rclone/rclone.conf):
[scaleway]
type = s3
provider = Scaleway
env_auth = false
access_key_id = <access_key_id>
secret_access_key = <secret_access_key>
region = fr-par
endpoint = s3.fr-par.scw.cloud
acl = public-read
storage_class = STANDARD
[minio]
type = s3
provider = Minio
env_auth = false
access_key_id = <access_key_id>
secret_access_key = <secret_access_key>
region = hyper2
endpoint = https://s3.650thz.de
location_constraint = hyper2
acl = public-read
Copying the existing user data from Scaleway to Minio was as simple as:
rclone copy --progress --transfers=8 scaleway:metalheadclub-media/custom_emojis/ minio:metalheadclub-media/custom_emojis/
rclone copy --progress --transfers=8 scaleway:metalheadclub-media/accounts/ minio:metalheadclub-media/accounts/
rclone copy --progress --transfers=8 scaleway:metalheadclub-media/site_uploads/ minio:metalheadclub-media/site_uploads/
rclone copy --progress --transfers=8 scaleway:metalheadclub-media/media_attachments/ minio:metalheadclub-media/media_attachments/
rclone copy --progress --transfers=8 scaleway:metalheadclub-media/imports/ minio:metalheadclub-media/imports/
rclone copy --progress --transfers=8 scaleway:metalheadclub-media/cache/accounts/ minio:metalheadclub-media/cache/accounts/
rclone copy --progress --transfers=8 scaleway:metalheadclub-media/cache/custom_emojis/ minio:metalheadclub-media/cache/custom_emojis/
I didn’t copy Mastodon’s cache/preview_cards and cache/media_attachments directories on purpose, since these directories make the majority of files and they will lose their validity in a couple of days anyway.
The file copying took several hours, esp. due to the large amount of files (not the file size!) and was fully transparent to the user. In the mean time, almost every request is served by my own Minio server and the traffic to my Scaleway bucket has drastically declined:
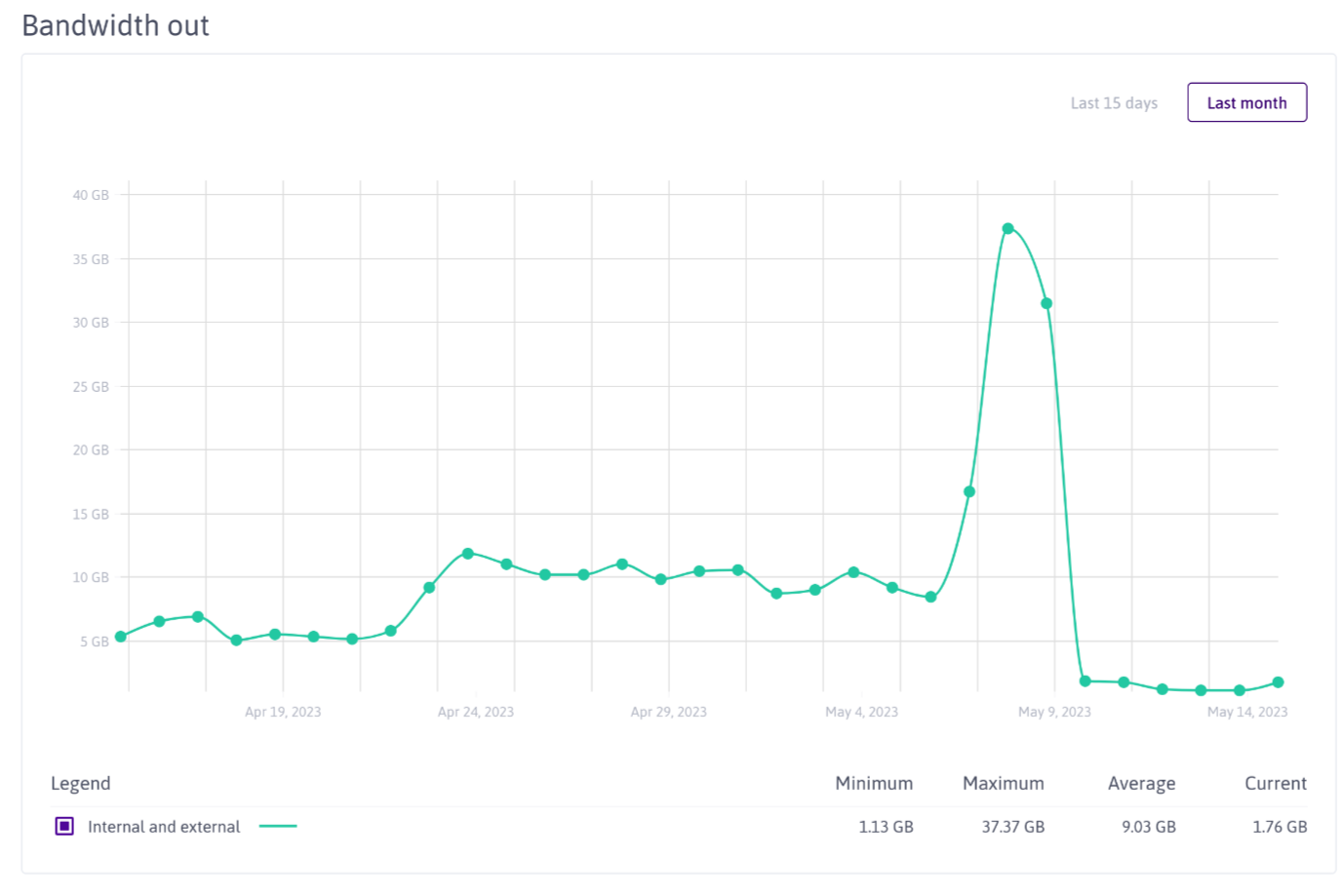
Scaleway bucket network traffic. Declining after a short period of intense file copying ;-)
The Scaleway bucket will not be needed anymore soon and I will drop it or use it as a backup storage.