


Scaling up your Mastodon Sidekiq workers for better performance
Mastodon has recently gained popularity amongst tech-savvy users after Elon Musk has bought Twitter. With November’s wave of new Mastodon users, many servers experienced mayor problems with their performance - so did metalhead.club, the Mastodon instance that I’m hosting myself. Here’s how I tackled performance issues on metalhead.club.
According to the Mastodon documentation there are 5 Services which might need re-scaling:
- PostgreSQL database (Persistent database)
- Redis Key-Value store (temporary database / job queue / cache)
- Puma Web Frontend (Serves the Web frontend)
- Streaming Server (Websocket Server for live updates)
- Sidekiq Job Queue (Runs background jobs such as upload processing and federation)
Especially in the night of November, 4th, metalhead.club’s Sidekiq workers were overloaded by jobs. Many new users registered on my instance and others connected to them by following their accounts. This creates a huge number of federation jobs that need to be transferred from and to my server. You can have a glance at your server’s Sidekiq panel by visiting https://<yourserver.tld>/sidekiq/busy/.
The status page will display information such as:
- How many Sidekiq processes are running
- How many Sidekiq threads are running
- How much those threads are utilized and
- Which queues they are processing.
If the thread utilization is near 100 %, federation jobs (and other processes) will need to wait for a bit until they are processed. On the night of November, 4th, the number of queued jobs rose quickly, esp. the number of pull jobs and default jobs. (See https://<yourserver.tld>/sidekiq/queues/). default jobs are jobs that are essential for the local instance, such as processing of notifications, timelines, likes and posts. This queue has the highest priority, while lower priority queues such as ‘pull’ are just run when everything else was processed (see: config/sidekiq.yml.
The default queue was filling up quickly. After a few hours more than 70,000 jobs were queued for processing while other sidekiq jobs were hardly run because of the priorities. This resulted in:
- Home timelines not being up to date (more then 2 hours delay)
- Federateds timeline not being up to date
- Notifications being delivered too late
- File / media upload taking forever
One Sidekiq process for all queues (default)
I’ve had a similar situation in April 2022, when Elon Musk spoke about buying Twitter for the first time. As a consequence the first wave of new users entered the Mastodon network. Back then is was sufficient to raise the number of Sidekiq workers by simple increasing the number of threads in the Sidekiq systemd service file /etc/systemd/system/mastodon-sidekiq.service:
[Unit]
Description=mastodon-sidekiq
After=network.target
[Service]
Type=simple
User=mastodon
WorkingDirectory=/home/mastodon/live
Environment="RAILS_ENV=production"
Environment="DB_POOL=75"
Environment="MALLOC_ARENA_MAX=2"
Environment="LD_PRELOAD=libjemalloc.so"
ExecStart=/home/mastodon/.rbenv/shims/bundle exec sidekiq -q default -c 75
TimeoutSec=15
I set DB_POOL=75 and -c 75, reloaded the systemd configuration and restarted the Sidekiq process:
systemctl daemon-reload
systemctl restart mastodon-sidekiq.service
https://<yourserver.tld>/pghero/connections and compare the current number of connections to the max number of connections in the PostgreSQL configuration.More Sidekiq Workers meant more parallel requests and therefore more processing power. This is the most simple way how to scale up your Mastodon server. You should try this at first.
One Sidekiq Process for each single queue
Also this time I tried to increase the number of Sidekiq threads - but it didn’t change anything: The queue grew and grew and more jobs were created then could be processed.
Reading the Mastodon documentation carefully, I noticed that there could be multiple Sidekiq processes, instead of just one (and multiple threads). I started creating multiple systemd services for (almost) each of the queue types. They only differed in the number of assigned threads (see previous snippet) and their queue config, e.g.:
ExecStart=/home/mastodon/.rbenv/shims/bundle exec sidekiq -q default -c 25
Starts a Sidekiq process that only processes the default queue with 25 threads. Whereas
ExecStart=/home/mastodon/.rbenv/shims/bundle exec sidekiq -q push -q pull -c 25
Runs both queues - push and pull.
Following the pattern, I created the following systemd service files:
- mastodon-sidekiq-default.service
- mastodon-sidekiq-mailers.service
- mastodon-sidekiq-pushpull.service
- mastodon-sidekiq-scheduler.service
- mastodon-sidekiq-ingress.service
After stopping/disabling the old Sidekiq services and starting/enabling the new ones, the situation relaxed a bit the next day. Jobs were processed more in parallel then before. E.g. push/pull jobs could be run regardless whether the default queue was full or not. Some timer later the push/pull queue was almost empty and most of the queued jobs were done.
Multiple Sidekiq processes and threads for one queue
But not the ingress queue. It was filling up again when American users started their day ~6 hours after European users. I had hundreds of Sidekiq threads ready to process the ingress queue. But looking at the Sidekiq control panel, I noticed something odd: Despite of hundreds or threads being ready to process data, only a fraction of them was actually busy. About 3/4 of the worker threads was not active. I couldn’t explain that behavior until I noticed this in htop:
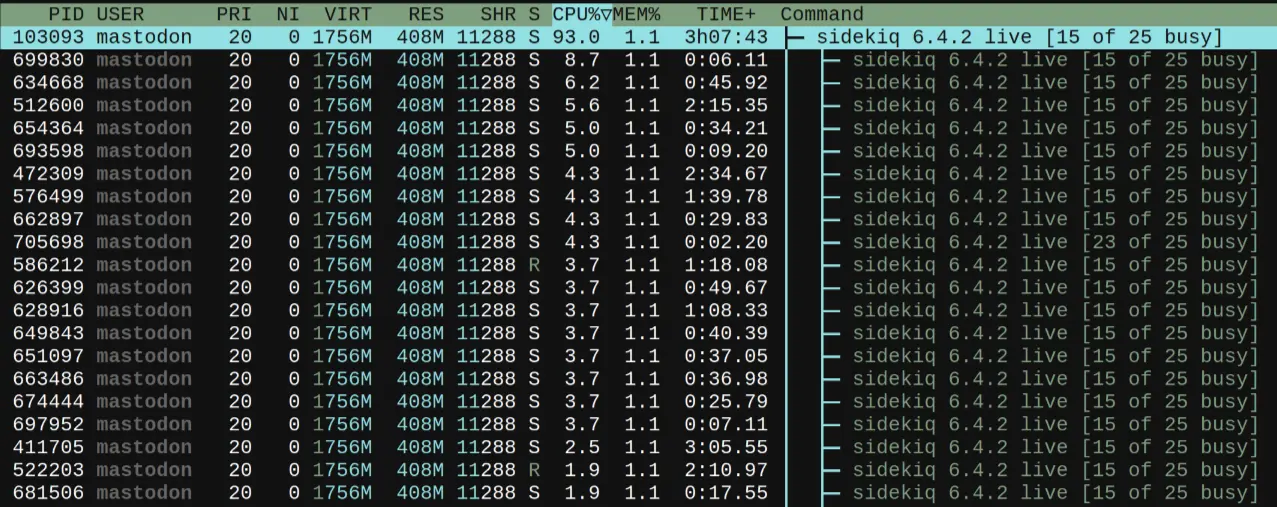
Sidekiq main process being at 93 %: Close to overload.
My Sidekiq Process for ingress was overloaded! As usual, the main process runs just on a single CPU core and then spawns its workers. They will then distribute across multiple CPU cores. As the main process was already consuming close to 100% of the CPU power, it was not able to distribute jobs to its workers, anymore. The threads were ready - but the main process could not keep up. That’s why so many threads just kept idling around doing nothing.
The Mastodon documentation does not state this, but you can also run multiple processes for a single queue!
Spreading the load of the ingress queue across multiple processes and threads would further improve the parallelization, so I once again re-arranged my systems service files and made copies of my mastodon-sidekiq-ingress.service file:
mastodon-sidekiq-ingress.servicemastodon-sidekiq-ingress-2.servicemastodon-sidekiq-ingress-3.servicemastodon-sidekiq-ingress-4.service- …
All those copies were then started in parallel - working on the same ingress queue. After a few more server-specific modifications, my Sidekiq control panel looks like this:
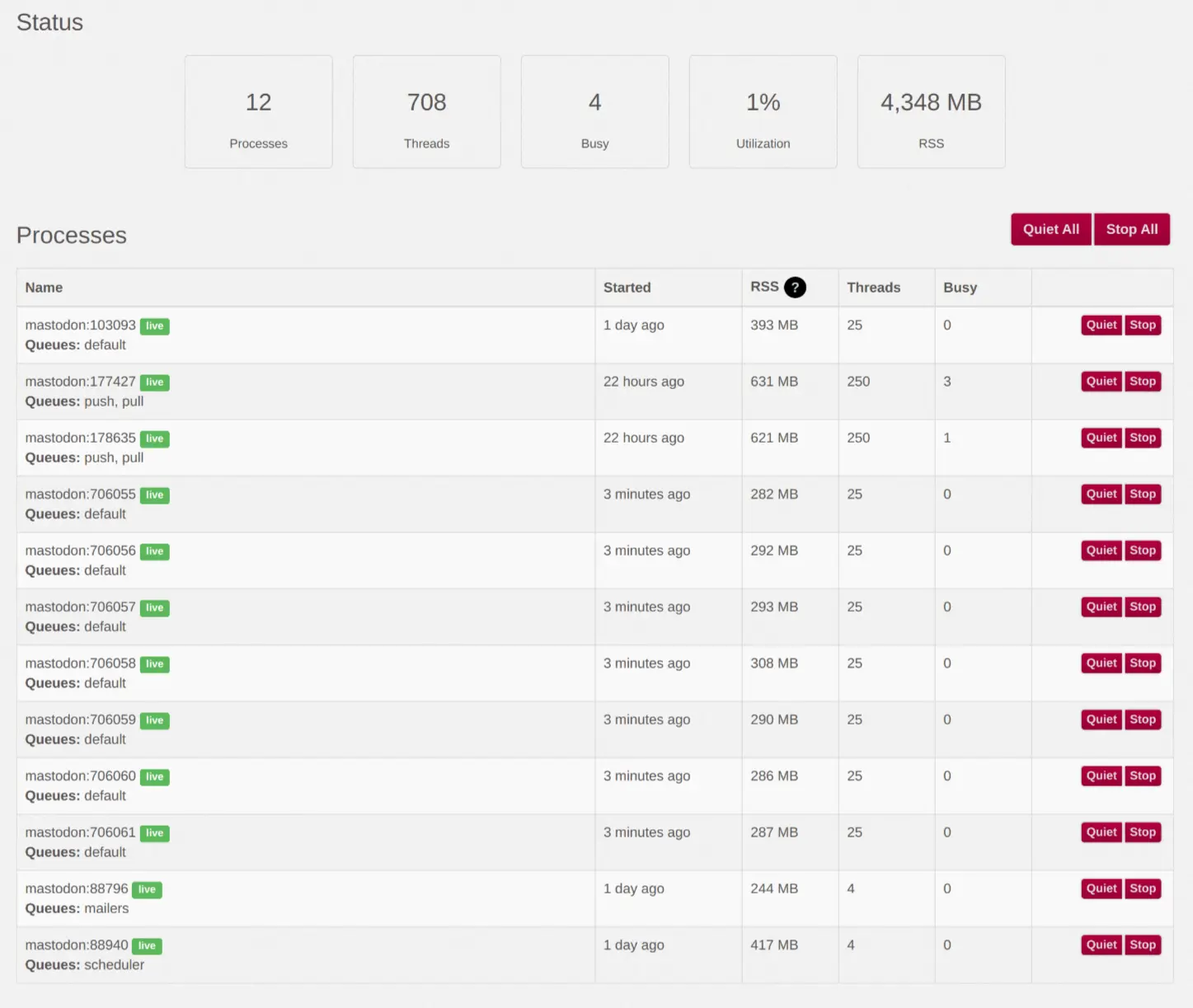
Beschreibung
Sidekiq could now use the full power of all the CPU cores and quickly processes all the queued jobs, until none of them were left. Now, if another 4,000 jobs is added from one second to next, my server is capable of processing the load within seconds. No more delay in the timelines - no more hassle with the media upload!
scheduler queue!