


Mastodon: Adding S3 based cloud storage to your instance
My Mastodon instance metalhead.club exists since summer 2016 and seen several waves of new users - but never as many new users as in early November 2022. This has not only led to heavy CPU work on the servers (see my post about scaling up Mastodon’s Sidekiq Workers), but also to greater load on storage space. Mastodon uses a media cache that not only stores copies of preview images for posts containing links - but also copies of all media files that the server knows of. Before the user wave of late 2020 metalhead.club’s media cache was about 350 GB in size with a cache retention time of 60 days. Quickly the numbers escalated and after a few days we were already at 400 GB - and after about 3 weeks we had more than 550 GB of cached media files. Not with 60 days retention time - but with 30 only.
Despite I added hundreds of GB of new storage space, the cache showed no signs of shrinking in the near future, so decided to offload the storage to an S3 storage provider. The local disks would have been full a few days later.
… and here’s how it works:
Choosing an S3 compatible provider
S3 is a storage type / protocol which origins from Amazon, but as I wanted a EU-based company to host my files, I looked for a compatible alternative. Luckily there are several S3 compatible storage providers in the EU, as this list reveals: https://european-alternatives.eu/alternative-to/amazon-s3
My top choices were Scaleway and IONOS. Scaleway is a French Hosting company and since their prices are even more affordable compared to IONOS’s prices, I picked Scaleway as my S3 bucket provider. Reviews on Scaleway are very mixed and you might get the impression that their customer service is not very helpful - but for the last 2 weeks my S3 bucket has been running just fine and there was no reason to call for help. We’ll see if Scaleway stays my S3 bucket provider or I will switch to IONOS instead.
The following steps will relate to Scaleway S3, but should be more or less applicable to other storage providers as well. You might need to change some details only.
Creating an S3 bucket
Creating a bucket is easy: Pick a name for your S3 bucket and make it look like a suitable subdomain or directory name. If you name your bucket “myinstance-media”, you will be able to access the Bucket via those two URLs:
(… assuming you’ve picket the fr-par availability region)
The Bucket visibility setting should be set to private instead of public. This will not change the accessibility of any media file! The private setting just makes sure that there is not list of file contents available to the public. While we want individual files to be publicly accessible by URL, we don’t want to help scrapers by handing them out a list of all available files.
Creating an Nginx Proxy for the S3 bucket
Usually web browsers would receive the corresponding S3 URL of a media file and directly download the file from one of the URLs mentioned earlier. Because every file would need to be downloaded on every user device at least once, a lot of traffic would be generated - and outgoing traffic costs money. Therefore I implemented an S3 proxy with Nginx. Media assets are not directly downloaded from the S3 storage, but the webbrowsers will download from https://media.metalhead.club. If a new media file should be downloaded, the Nginx proxy will pass the request to the S3 storage and cache the contents locally. The next time a request for the same file comes in, Nginx will directly send the cached version of the file instead of re-downloading it from S3. This way a lot of traffic from the S3 bucket can be saved.
Here’s my Nginx config:
proxy_cache_path /tmp/nginx-cache-instance-media levels=1:2 keys_zone=s3_cache:10m max_size=10g
inactive=48h use_temp_path=off;
server {
listen 80;
listen [::]:80;
server_name media.metalhead.club;
access_log off;
error_log /var/log/nginx/media.metalhead.club-error.log;
root /home/mastodon/live/public/system;
set $s3_backend 'https://instance-media.s3.fr-par.scw.cloud';
keepalive_timeout 30;
location = / {
index index.html;
}
location / {
try_files $uri @s3;
}
location @s3 {
limit_except GET {
deny all;
}
resolver 9.9.9.9;
proxy_set_header Host 'instance-media.s3.fr-par.scw.cloud';
proxy_set_header Connection '';
proxy_set_header Authorization '';
proxy_hide_header Set-Cookie;
proxy_hide_header 'Access-Control-Allow-Origin';
proxy_hide_header 'Access-Control-Allow-Methods';
proxy_hide_header 'Access-Control-Allow-Headers';
proxy_hide_header x-amz-id-2;
proxy_hide_header x-amz-request-id;
proxy_hide_header x-amz-meta-server-side-encryption;
proxy_hide_header x-amz-server-side-encryption;
proxy_hide_header x-amz-bucket-region;
proxy_hide_header x-amzn-requestid;
proxy_ignore_headers Set-Cookie;
proxy_pass $s3_backend$uri;
proxy_intercept_errors off;
proxy_cache s3_cache;
proxy_cache_valid 200 304 48h;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_cache_lock on;
proxy_cache_revalidate on;
expires 1y;
add_header Cache-Control public;
add_header 'Access-Control-Allow-Origin' '*';
add_header X-Cache-Status $upstream_cache_status;
}
}
(HTTPS is handled by another upstream Nginx instance)
Make sure to update both instance-media.s3.fr-par.scw.cloud URLs and the FQDN media.metalhead.club according to your environment. My configuration will keep media files cached for 48 hours before they will be dropped from the cache.
Two noteworthy lines are root /home/mastodon/live/public/system; and try_files $uri @s3;. They will make Nginx first look for a file in the local non-S3 storage. If a file exists there, S3 and the cache will not be tried. This mechanism enables a smooth transition between the local media cache and the remote S3 cache, since data transfer / sync can take hours or even days, depending on the Mastodon media cache size.
Enabling S3 stroage support in Mastodon
I enabled S3 support in Mastodon by editing the .env.production file in /home/mastodon/live:
S3_ENABLED=true
S3_BUCKET=instance-media
AWS_ACCESS_KEY_ID=<accesskey>
AWS_SECRET_ACCESS_KEY=<secretkey>
S3_ALIAS_HOST=media.metalhead.club
S3_HOSTNAME=media.metalhead.club
S3_REGION=fr-par
S3_ENDPOINT=https://s3.fr-par.scw.cloud
accesskey and secretkey need to be replaced by proper API access keys. You can find more information about the keys here: https://www.scaleway.com/en/docs/console/my-project/how-to/generate-api-key/
After having modified the config file, restart all mastodon processes!
Syncing your local data to S3
It’s now time to sync your local Mastodon media cache data to your S3 bucket. Follow the steps of the Scaleway How-To to set up the aws tool. When done, run the following steps to sync your data (better use a tmux / screen session - this make take a looong time!):
cd /home/mastodon/live
aws s3 sync --acl public-read public/system/ s3://instance-media --endpoint=https://s3.fr-par.scw.cloud
The --acl public-read is especially important, because uploaded files will only be available publically if the public-read acl is set for each file individually. If you miss to do that, you will need to re-upload all files. Guess how I learned that … ;-)
No worries, if the upload takes many hours. As mentioned before, Nginx will keep serving the media files from the local storage if it doesn’t find any suitable file in the S3 bucket, so the transition will be transparent to the users.
Checking if it works
Apart from the obvious (“do all the media files on my instance still load properly?”) you can also check if your web browser fetches images files from the correct location, e.g. media.metalhead.club, and if caching is successful. Open the web developer tools and reload the page while observing the network resources being loaded:
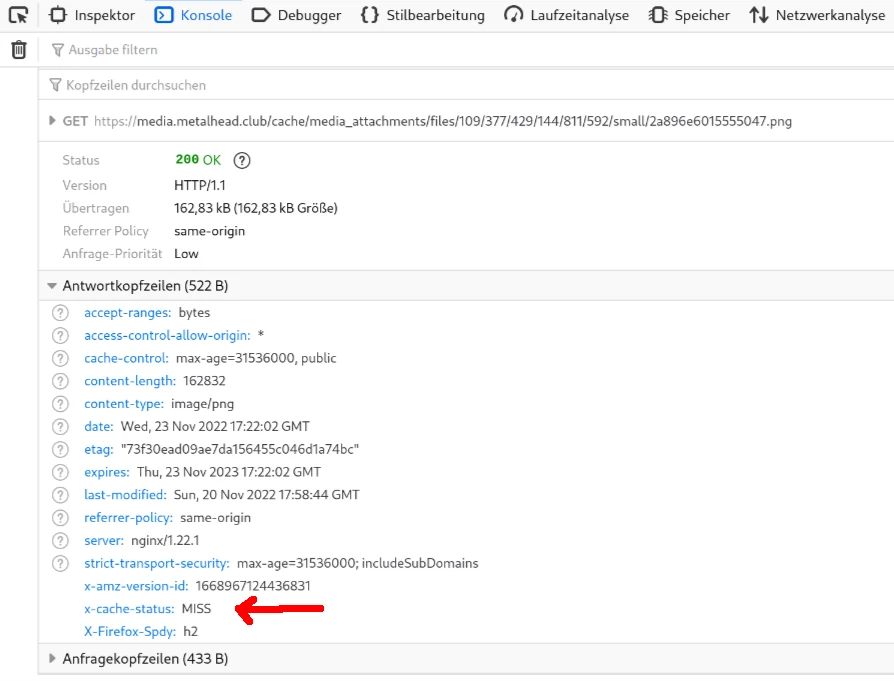
A media resource being loaded for the first time
Check the response headers: The x-cache-status attribute should be miss the first time an image os loaded from the server. If you pick the URL of the image and download it in another tab (or reload the page), the attribute should switch to hit. That means that the image was not delivered by the S3 bucket, but by the local Nginx cache - exactly what we wanted to achieve!
Useful resources: